Medical multiple-choice question answering (MCQA) benchmarks report near-human accuracy, with some approaching saturation and fueling claims of clinical readiness. Yet a single accuracy score is a poor proxy for competence: models that change answers under minor perturbations cannot be considered reliable. We argue that reliability underpins accuracy—only consistent predictions make correctness meaningful.
We release ReMedQA, a benchmark suite that augments three standard medical MCQA datasets with open-answer variants and systematically perturbed items. Building on this, we introduce ReAcc and ReCon, two reliability metrics: ReAcc measures the proportion of questions answered accurately across all variations, while ReCon measures the proportion answered consistently regardless of correctness.
Our evaluation shows that high MCQA accuracy masks low reliability: models remain sensitive to format and perturbation changes, and domain specialization offers no robustness gain. MCQA underestimates smaller models while inflating large ones that exploit structural cues—with some producing correct answers without seeing the question.
These findings show that, despite near-saturated accuracy, we are not yet done with medical multiple-choice benchmarks.
| ReMedQA | Pro Med. | College Med. | Anatomy | Clinical | Biology | Genetics | MMLU Avg | MedQA | MedMCQA | Avg | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ReAcc | ReCon | ReAcc | ReCon | ReAcc | ReCon | ReAcc | ReCon | ReAcc | ReCon | ReAcc | ReCon | ReAcc | ReCon | ReAcc | ReCon | ReAcc | ReCon | ReAcc | ReCon | |
| Large Models | ||||||||||||||||||||
| GPT-5-mini 🧠 | 76.4 | 77.5 | 58.3 | 66.7 | 65.6 | 73.6 | 61.1 | 68.9 | 67.0 | 71.3 | 85.4 | 86.6 | 69.0 | 74.1 | 65.9 | 68.2 | 39.1 | 46.0 | 58.0 | 62.8 |
| GPT-OSS-120B 🧠 | 72.0 | 76.8 | 59.8 | 65.9 | 54.4 | 65.6 | 57.0 | 65.3 | 70.6 | 74.3 | 79.3 | 84.1 | 65.5 | 72.0 | 62.4 | 67.6 | 34.4 | 43.9 | 54.1 | 61.2 |
| Gemini-2.5-Flash 🧠 | 57.9 | 60.5 | 46.2 | 55.7 | 52.0 | 62.4 | 46.6 | 52.8 | 60.6 | 67.9 | 72.0 | 73.2 | 55.9 | 62.1 | 47.6 | 50.7 | 33.2 | 39.4 | 45.6 | 50.7 |
| GPT-OSS-20B 🧠 | 62.6 | 66.7 | 47.7 | 55.7 | 52.0 | 59.2 | 48.7 | 54.9 | 60.6 | 65.1 | 64.6 | 75.3 | 56.0 | 62.8 | 49.4 | 54.0 | 24.9 | 30.4 | 43.4 | 49.1 |
| Llama-3.3-70B | 53.5 | 56.5 | 34.8 | 40.9 | 48.8 | 53.6 | 42.5 | 45.6 | 55.0 | 56.0 | 63.4 | 64.6 | 49.7 | 52.9 | 34.0 | 37.9 | 23.6 | 28.6 | 35.8 | 39.8 |
| Small Models | ||||||||||||||||||||
| Llama-3-8B | 9.8 | 17.7 | 9.8 | 15.9 | 12.8 | 27.2 | 11.9 | 20.2 | 15.6 | 25.7 | 23.2 | 37.8 | 13.9 | 24.1 | 6.1 | 11.9 | 6.8 | 16.0 | 8.9 | 17.3 |
| Llama3-Med42-8B 💚 | 15.7 | 18.9 | 18.2 | 24.6 | 20.8 | 29.6 | 17.6 | 24.4 | 15.6 | 22.9 | 24.4 | 36.6 | 18.7 | 26.2 | 9.1 | 13.2 | 10.8 | 18.2 | 12.9 | 19.2 |
| Phi-3.5-mini | 23.6 | 25.6 | 9.8 | 24.2 | 26.4 | 35.2 | 18.1 | 26.9 | 29.4 | 32.1 | 19.5 | 40.2 | 21.1 | 30.7 | 12.3 | 15.4 | 11.0 | 13.8 | 14.8 | 20.0 |
| MediPhi-3.8B 💚 | 11.8 | 16.1 | 14.4 | 18.2 | 20.0 | 27.2 | 18.7 | 20.2 | 21.1 | 23.9 | 24.4 | 29.3 | 18.4 | 22.5 | 8.6 | 13.4 | 7.9 | 11.5 | 11.6 | 15.8 |
| Gemma-3-4B | 5.9 | 8.3 | 5.3 | 9.8 | 16.0 | 19.2 | 6.7 | 9.4 | 12.8 | 17.4 | 23.2 | 23.8 | 11.7 | 14.6 | 3.3 | 6.2 | 3.8 | 6.8 | 6.3 | 9.2 |
| MedGemma-4B 💚 | 2.8 | 4.3 | 2.3 | 5.3 | 4.8 | 10.4 | 3.6 | 5.7 | 6.4 | 9.2 | 8.5 | 11.0 | 4.7 | 7.6 | 2.5 | 5.8 | 2.7 | 5.3 | 3.3 | 6.2 |
Note: 🧠 Reasoning-focused LLMs; 💚 Medical-specialized LLMs.
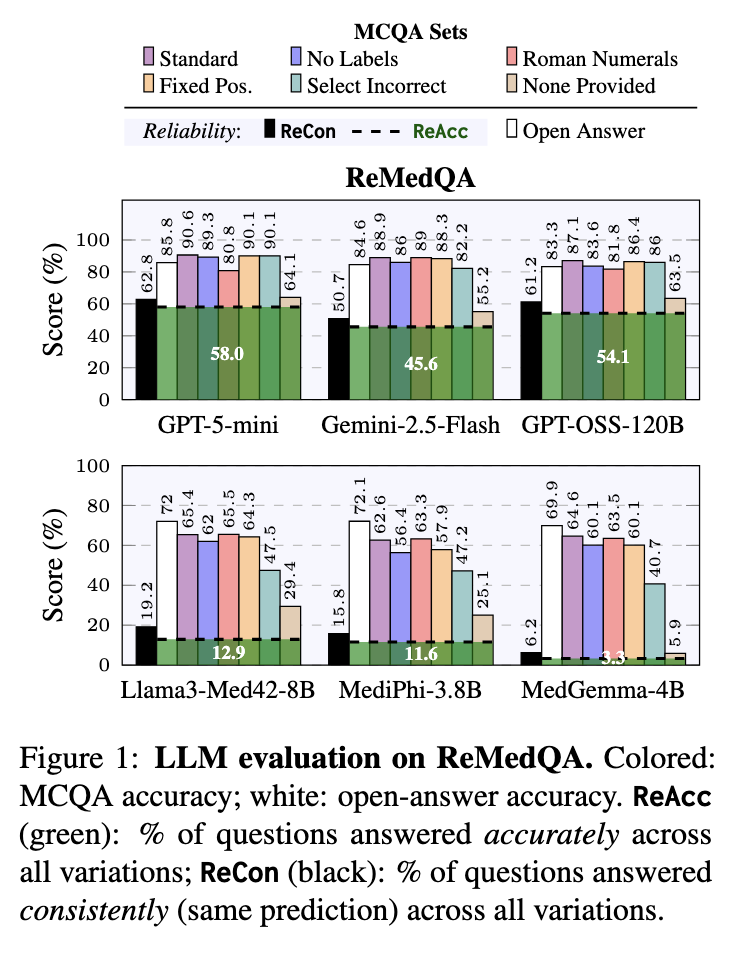
ReMedQA evaluates medical AI models in two key ways: Closed format, where models choose from multiple-choice options, and Open format, where models generate free-form answers that are then matched to the original options. This dual approach helps us understand how reliably models can answer medical questions.
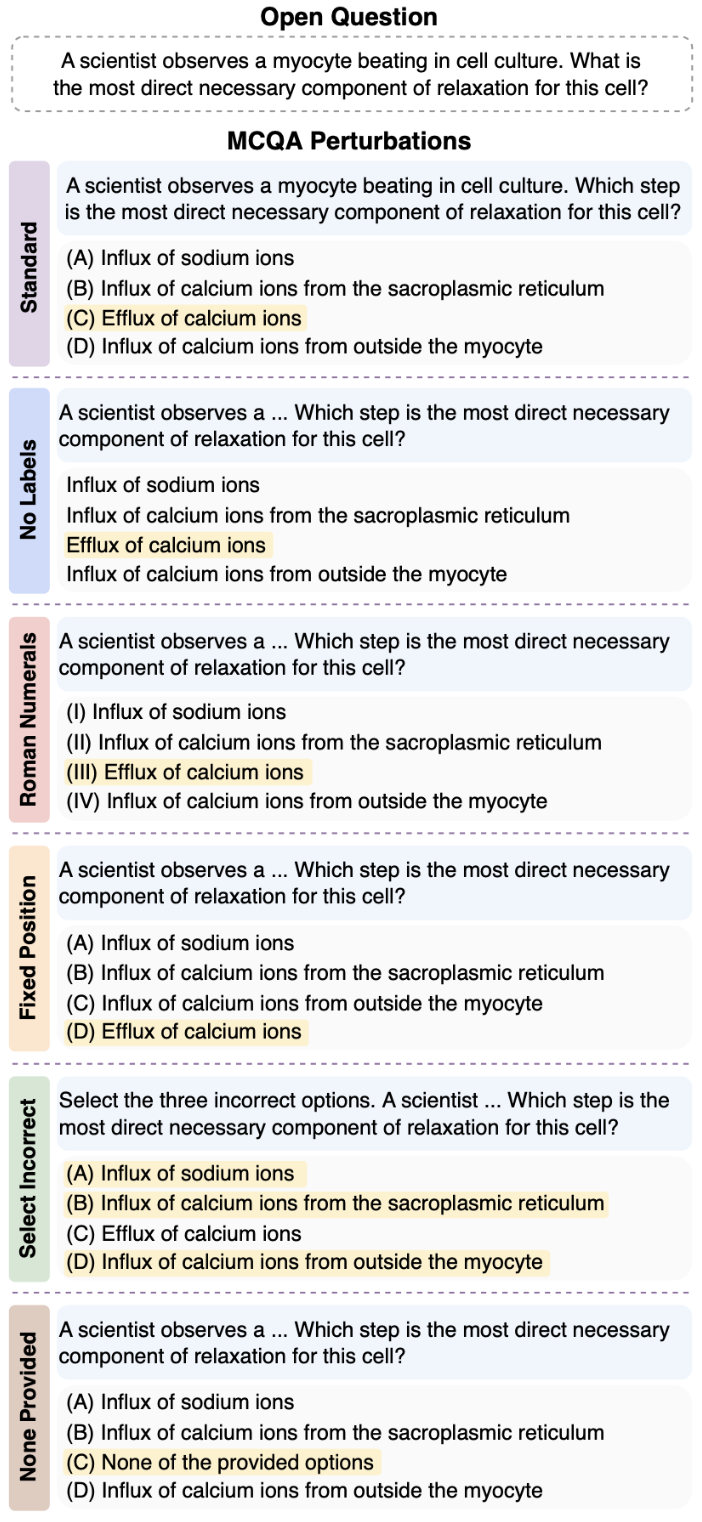
To truly test reliability, we created five different versions of each question that mean the same thing but look different on the surface. If a model is truly reliable, it should give consistent answers across all these variations. Think of it like asking the same medical question in slightly different ways - a trustworthy expert should recognize they're the same question and give the same answer every time.
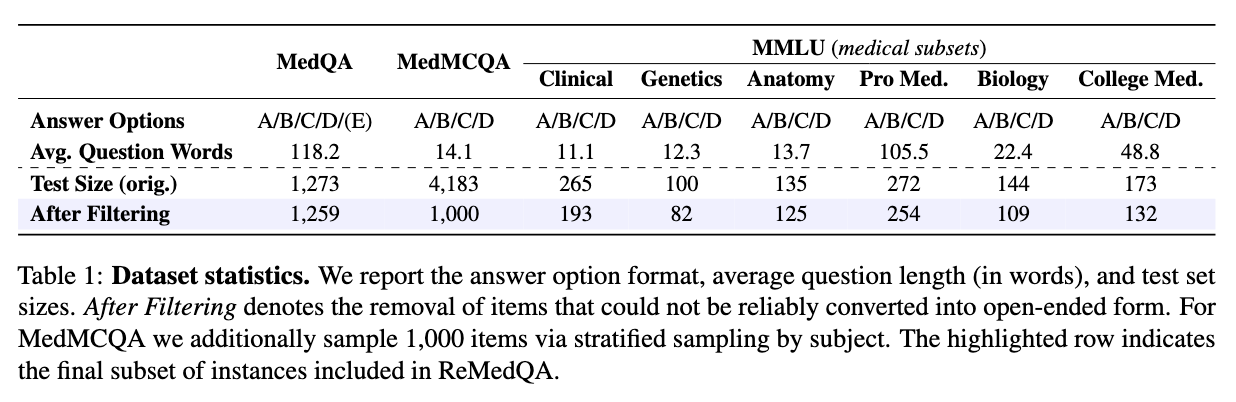
We considered the following closed (MCQA) perturbations:To build ReMedQA, we draw from three prominent medical corpora, yielding eight English-language MCQA tasks spanning specialties such as genetics, anatomy, and clinical reasoning. These datasets reflect both real-world scenarios encountered by medical professionals and exam formats commonly used in licensing and entrance tests. We focus only on datasets with 4-option choice format, to ensure consistency across our findings and structural compatibility with our framework.
To measure how reliable medical AI models really are, we created two key metrics that go beyond simple accuracy. These metrics check whether models give consistent and correct answers across all seven versions of each question.
Together, these metrics reveal the true reliability of medical AI models. A high standard accuracy score might look impressive, but ReCon and ReAcc show whether that performance is stable and dependable - exactly what we need for real-world healthcare applications.
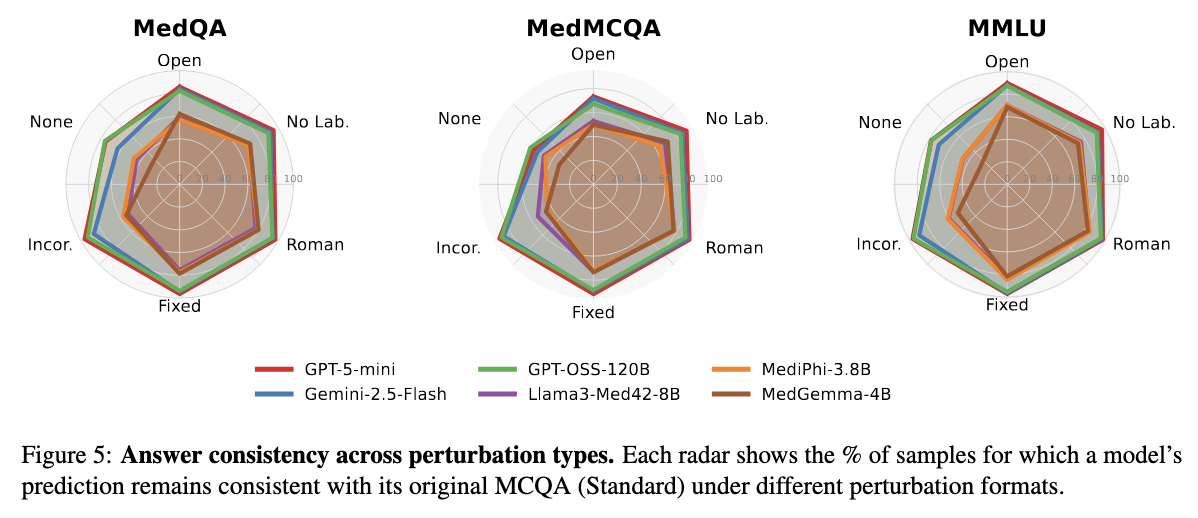
Our results reveal a surprising disconnect: models can score very high on accuracy but still fail dramatically on reliability. Even when models answer most questions correctly, they often give different answers when we perturbate the same question. This instability is especially pronounced in smaller models, whose predictions can flip completely based on minor format changes.
We also found a systematic gap between open-ended and multiple-choice performance. Large models benefit from the structured format of multiple-choice questions, while smaller models actually perform worse with multiple choices than when generating free-form answers - suggesting they get confused by the extra options and formatting.
Most importantly, even frontier models with near-perfect accuracy scores show only modest reliability. The gap between their accuracy and reliability metrics reveals that consistency - not accuracy - is the real bottleneck for building trustworthy medical AI. A model might know the right answer, but if it can't reliably give that answer across different presentations of the same question, it's not ready for real-world healthcare use.
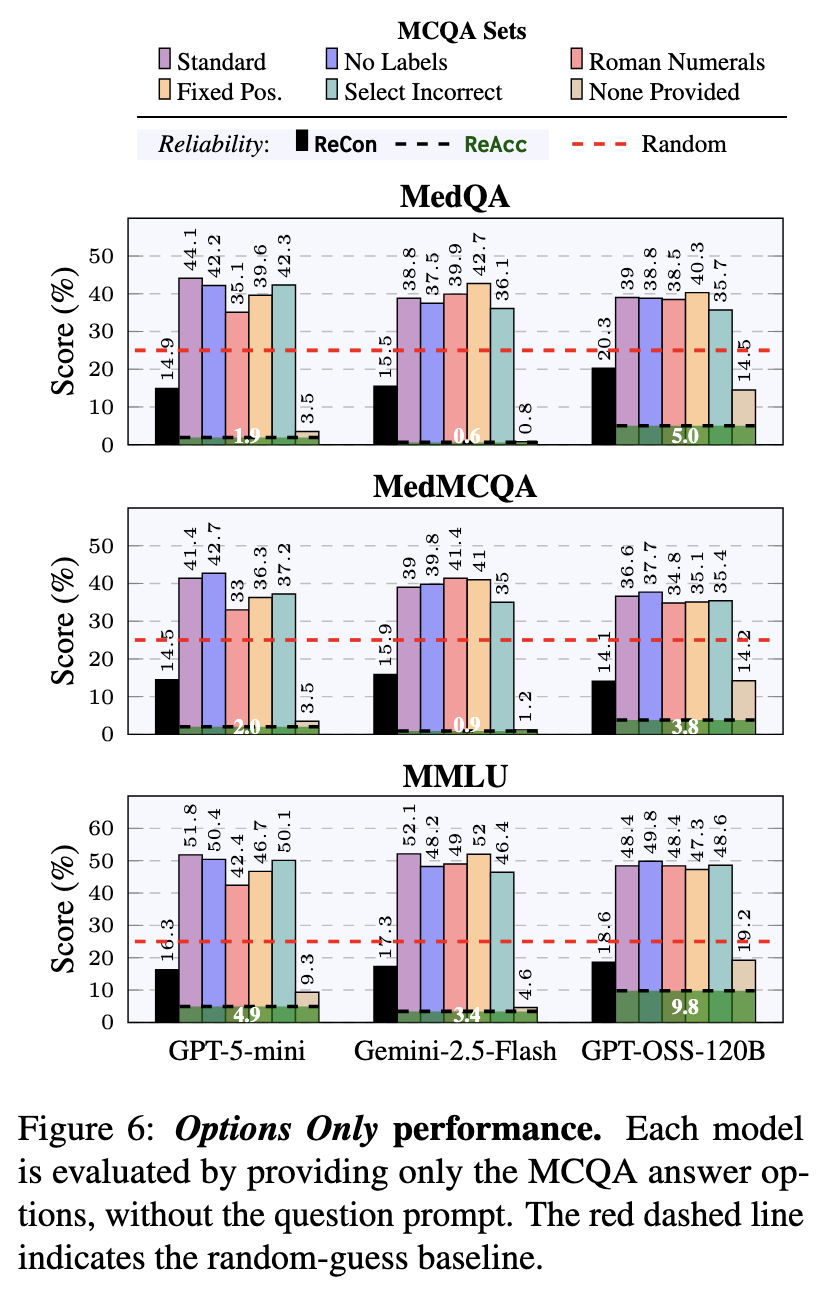
We tested something surprising: what happens if we give models only the answer choices without showing them the actual medical question? Shockingly, models still scored 40-50% correct - far better than random guessing! This means they're picking up on patterns and shortcuts in how answers are written, rather than truly understanding the medicine.
However, when we apply our reliability tests to these "options-only" answers, the models' consistency completely falls apart. This proves they're using superficial tricks rather than real medical knowledge - a serious concern for healthcare applications.
Our analysis reveals that the "None Provided" variation - where the correct answer is replaced with "None of the provided options" - causes the biggest drop in consistency across all models. This forces models to reason about what's missing rather than just picking from what's there.
Interestingly, the "Select Incorrect" variation (asking for wrong answers instead of right ones) mainly trips up smaller models. Larger models can handle this task reversal much better, showing they understand the task more deeply.
Across different medical datasets like MedQA and MedMCQA, models show similar consistency patterns within each format. However, MedMCQA becomes much harder when models need to stay consistent across multiple formats at once - revealing hidden complexity that single-format testing misses.
The bottom line: OpenAI's models (GPT-5-mini, GPT-OSS-120B) remain the most reliable across all our tests, while smaller models show bigger drops in consistency, confirming that reliability still improves with model size.
You might expect that AI models specifically trained on medical content (like MediPhi and MedGemma) would be more reliable than general-purpose models. Surprisingly, that's not what we found. Medical-specialized models don't show a clear reliability advantage over their general-purpose counterparts.
Despite being fine-tuned on medical texts and data, these specialized models often score lower on both ReAcc and ReCon compared to general models. This reveals an important lesson: simply exposing a model to medical content isn't enough to make it reliable. True robustness in medical question-answering requires broader reasoning abilities and generalization skills that go beyond memorizing medical terminology and facts.
This finding challenges the assumption that domain specialization automatically leads to better performance. For healthcare AI, we need models that can reason consistently across different formats and presentations - a capability that requires more than just medical training.
@inproceedings{cocchieri-etal-2026-remedqa,
title = "ReMedQA: Are We Done With Medical Multiple-Choice Benchmarks?",
author = "Cocchieri, Alessio and
Ragazzi, Luca and
Tagliavini, Giuseppe and
Moro, Gianluca",
booktitle = "Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = mar,
year = "2026",
address = "Rabat, Morocco",
publisher = "Association for Computational Linguistics"
}